Seit Jahrhunderten sind Papier und Drucktechniken für die Menschheit die
Grundlage für die Verbreitung von Information. Physische Dokumente genießen dabei ein hohes
Vertrauen. Was „schwarz auf weiß“ vorliegt, hat Gewicht. Doch die Fälschung von Dokumenten ist
wahrscheinlich so alt wie die Geschichte der Schrift und die Frage nach deren Urheber daher von
Bedeutung. Die technologische Entwicklung erlaubt es heutzutage auch Privatpersonen mit
handelsüblichen Geräten qualitativ hochwertige Ausdrucke und Duplikate zu erstellen. Zusätzlich
ermöglicht einfach zu bedienende Bildbearbeitungssoftware heute einfacher denn je, Bilder und
Dokumente zu manipulieren, um beispielsweise einen gefälschten Identitätsnachweis herzustellen.
Daneben spielen Druckerzeugnisse auch im Zusammenhang mit anderen Straftaten eine Rolle, z. B.
bei Nachdrucken urheberrechtlich geschützter Inhalte oder als Beweisstück in einem Kriminalfall.
In all diesen Fällen wäre es für die Strafverfolgungsbehörden hilfreich, das Gerät oder Modell
zu identifizieren, mit dem solche Dokumente gedruckt wurden.
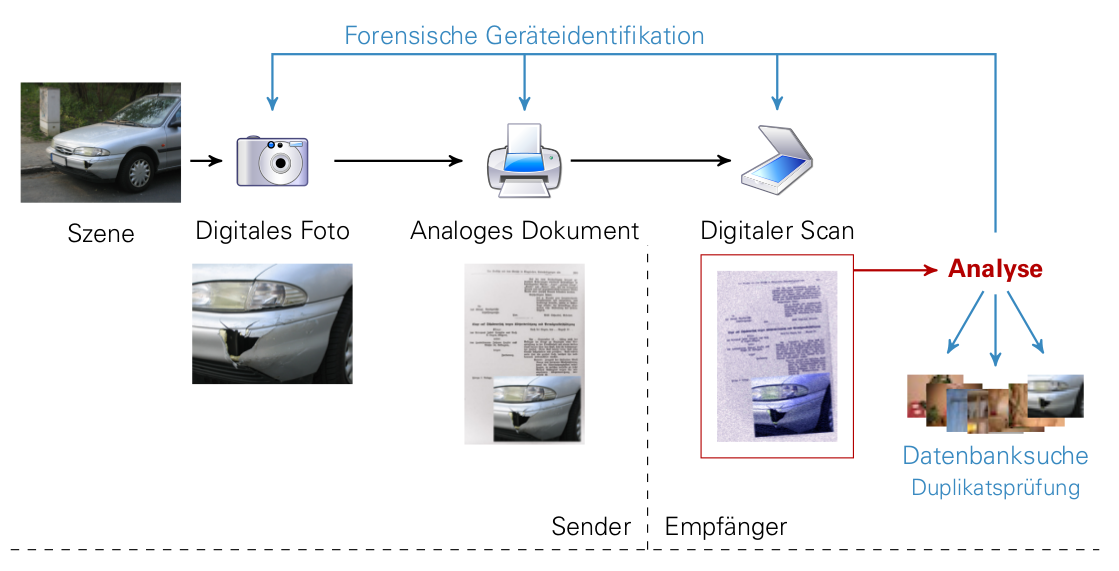 Der erste Teil des Projektes erforscht den Bereich der Druckerforensik. Hierbei werden
insbesondere die Fragestellungen nach der Identifikation des Druckgerätes sowie der genutzten
Drucktechnologie untersucht. Das Augenmerk liegt dabei auf der Extraktion von im Druckprozess
entstandener Artefakte. Diese entstehen insbesondere durch elektromechanische Mängel sowie den
gerätespezifische Aufbau. Erforscht werden sollen Artefakte, welche stabil und z. B.
modellspezifisch auftreten und somit als intrintische Signatur für das bestimmte Druckermodell
verwendet werden können. Die Extraktion soll hier mit handelsüblichen Aufnahmegeräten und
Bildverarbeitungstechniken erfolgen. Zeitgleich erforscht die Firma Dence als
Kooperationspartner die forensische Analyse von Scangeräten.
Der erste Teil des Projektes erforscht den Bereich der Druckerforensik. Hierbei werden
insbesondere die Fragestellungen nach der Identifikation des Druckgerätes sowie der genutzten
Drucktechnologie untersucht. Das Augenmerk liegt dabei auf der Extraktion von im Druckprozess
entstandener Artefakte. Diese entstehen insbesondere durch elektromechanische Mängel sowie den
gerätespezifische Aufbau. Erforscht werden sollen Artefakte, welche stabil und z. B.
modellspezifisch auftreten und somit als intrintische Signatur für das bestimmte Druckermodell
verwendet werden können. Die Extraktion soll hier mit handelsüblichen Aufnahmegeräten und
Bildverarbeitungstechniken erfolgen. Zeitgleich erforscht die Firma Dence als
Kooperationspartner die forensische Analyse von Scangeräten.
Der zweite Teil des Projektes beschäftigt sich mit der Erforschung einer Druck-Scan robusten
Duplikatsprüfung. Hierbei stellen die Erkenntnisse über auftretende Artefakte im Druck- sowie im
Scanprozess eine solide Basis dar. Als Anwendungsfall sei hier der typische Ablauf einer
Versicherung genannt. Im Schadensfall würde der Versicherte den Schaden fotografieren und die
Fotos zusammen mit Formularen der Versicherung postalisch zuschicken. Anschließend werden die
Dokumente bei der Versicherung eingescannt. Der Sachbearbeiter begutachtet die Schadensmeldungen
anhand der digitalen Reproduktion am Computer. Aufgrund der Druck- und Scanprozesse, die das
usprüngliche Dokument durchlaufen hat, sind Fragen zur Authentizität des Dokuments nur sehr
schwierig zu beantworten. Ziel der Analysen ist die Umsetzung einer Ähnlichkeitsbildersuche, die
gegenüber Störungen eines Druck-Scan-Vorgangs resistent ist, d.h. Fotos auch zuverlässig
einander zuordnen kann, falls nur eine ausgedruckte und redigitalisierte Version vorliegt. Die
Duplikatsprüfung muss in der Lage sein, für ein zu testendes Bild in kürzester Zeit mögliche
Duplikate aus einem Datenbestand von Millionen von Bildern zu finden. Technisch geschieht dies
mithilfe eines eindeutigen Bildhashes. Die große Herausforderung für das Druck-Scan-Szenario ist
die Berechnung des Bildhashs. Der Hashwert muss zwischen einem ausgedruckten und
redigitalisierten Bild und der originalen Kameraaufnahme gleich oder sehr ähnlich sein, damit
diese einander zugeordnet werden können. Eine weitere Schwierigkeit stellt die wünschenswerte
Duplikatserkennung auch bei kleinen Manipulationen dar, z. B. ein Autokratzer. Demgegenüber
steht die Anforderung der Vermeidung von Fehlzuordnungen direkt entgegen.
Stephan Escher, Thorsten Strufe. Robustness analysis of a passive printer identification scheme for halftone images. In IEEE International Conference on Image Processing (ICIP), 2017
Timo Richter* , Stephan Escher* , Dagmar Schönfeld, Thorsten Strufe. Forensic Analysis and Anonymisation of Printed Documents. In Proceedings of 6th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ’18), 2018
Stephan Escher, Patrick Teufert, Lukas Hain, Thorsten Strufe. Twizzle - A Multi-Purpose Benchmarking Framework for Semantic Comparisons of Multimedia Object Pairs. In Proceedings of 3rd International Workshop on Multimedia Privacy and Security (MPS), 2020
Stephan Escher, Patrick Teufert, Robin Hermann, Thorsten Strufe. You've got nothing on me! Privacy Friendly Face Recognition Reloaded. In Proceedings of 3rd International Workshop on Multimedia Privacy and Security (MPS), 2020
Beschreibung: Das DEDA-Toolkit ermöglicht die automatische Extraktion, Dekodierung und Anonymisierung von Yellow Dots.
Wenn Sie diese Software verwenden, zitieren Sie bitte das Papier:
Timo Richter*, Stephan
Escher*, Dagmar Schönfeld and Thorsten Strufe. 2018. Forensic Analysis and Anonymisation of
Printed Documents. In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia
Security (IH&MMSec '18). ACM, New York, NY, USA, 127-138. DOI
Github-Link Download Windows Exe
Beispiel für Ubuntu 16.10 oder neuer
Beispiel für Windows 10
Beschreibung: Das Modulare Image Hashing Benchmarking System MIHBS ermöglicht den Vergleich und die Bewertung von Perceptual Image Hashing Ansätzen hinsichtlich ihrer Robustheit gegenüber spezifischen wahrnehmungserhaltenden Transformationen, ihrer Sensitivität und gelabelten Anwendungsdatensätzen.
3f32f892d1c64a97890af89746041b69
Beschreibung: Ein modulare Challenge-Response Benchmarking System für paarweise Objektvergleiche. Nützlich um beispielsweise Perceptual Hashing, Drucker Forensik oder Face Recognition Algorithmen vergleichen und evaluieren zu können.
Beschreibung: Verschiedene Datensets für die Entwicklung und Evaluierung von Drucker Forensik Algorithmen.
Nöthnitzer Str. 46
Andreas-Pfitzmann-Bau (APB)
Raum: 3072
01187 Dresden
+49 351 463 38111

