For hundreds of years, paper and printing techniques are the foundation for
distribution of information. Thereby, physical documents enjoy high confidence. To have
something in „black and white“ carries significance. But forgery or alteration of documents are
nearly as old as the history of writing. Hence the question for the originator is important.
Nowadays, because of continual technological development, even individuals can print
high-quality documents and duplicates. This can be done with cheap and customary devices. In
addition image processing software, like gimp or photoshop, allows to manipulate documents and
images easily. Therefore printed documents are often an issue in crimes, e.g. faked proof of
identity, copyright theft, or as exhibit in a criminal case. In all this cases it could be
useful for law enforcement agencies to, e.g., identify the device or model which was used to
print the questionable document.
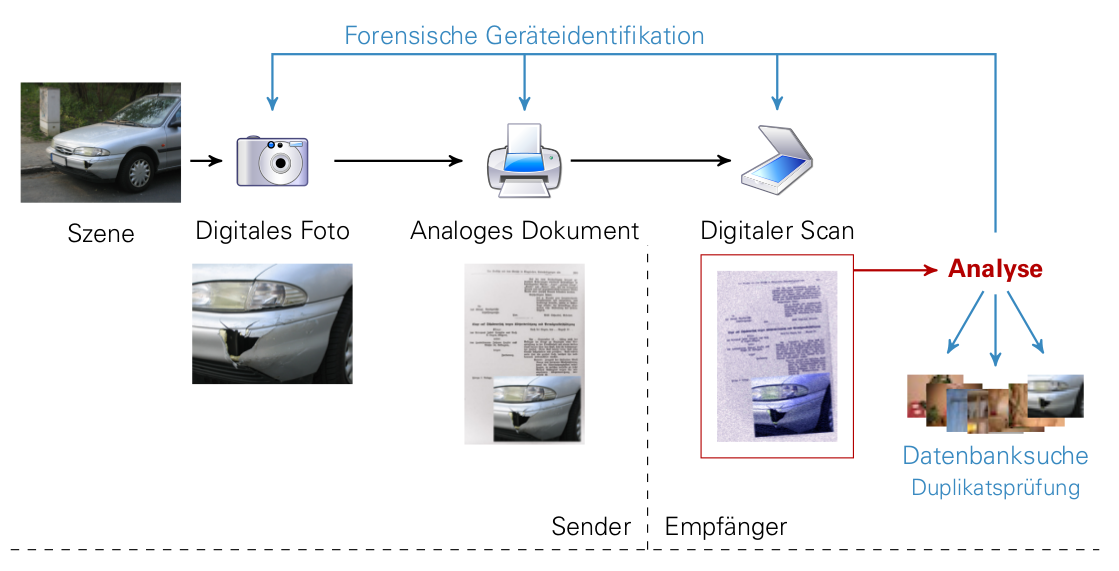 In the first part of the project we will investigate the area of printer forensics. Thereby
especially the identification of the printing technology and the printer (brand, model, device
itself) will be analysed. The primary focus of the research lies on the extraction of artefacts,
which are originated from the print process. These artefacts emerge particularly through
electromechanical imperfections and also through differences between constructions of printer
models. We try to find and analyse artefacts which are stable and e.g. model specific and
therefore usable as intrinsic signatures for a specific printer model. The extraction of these
signatures should be conducted with customary scanner devices and image processing techniques.
Simultaneously, the company Dence (cooperation partner) will investigate the scanner forensics.
In the first part of the project we will investigate the area of printer forensics. Thereby
especially the identification of the printing technology and the printer (brand, model, device
itself) will be analysed. The primary focus of the research lies on the extraction of artefacts,
which are originated from the print process. These artefacts emerge particularly through
electromechanical imperfections and also through differences between constructions of printer
models. We try to find and analyse artefacts which are stable and e.g. model specific and
therefore usable as intrinsic signatures for a specific printer model. The extraction of these
signatures should be conducted with customary scanner devices and image processing techniques.
Simultaneously, the company Dence (cooperation partner) will investigate the scanner forensics.
The second part of the project deals with research of print-scan resilient checks of duplicates.
Here the knowledge about artefacts which occur in the print and scan process represent a
reliable basis. As use case the typical workflow in an insurance can be mentioned. In the event
of damage, the insured person would take a photo of the damage and send it postal, together with
forms, to the insurance. Afterwards the insurance will scan these documents. The insurance staff
examines the event of damage on the basis of the digital reproduction. Because of the print and
scan processes, which the original document went through, the question of authenticity of the
document is difficulty to answer. Goal of the analysis is the implementation of an image search
for duplicates, which is resilient against the print and scan process. This means, that images
can also be matched, if only printed and re-digitized versions are available. The duplicate
testing must be able to check an image immediately against a data pool with millions of images.
From technical view, this will be realised with a distinct image hash. The challenge for the
print-scan scenario is the computation of this hash. The hash value has to be equal or very
similar between the original photo and the printed and re-digitized image, so that they can
matched. Another difficulty is a working check for duplicates also with slight manpulations in
the image (like a car scratch). All of this must be accomplished without matching false
positives.
Stephan Escher, Thorsten Strufe. Robustness analysis of a passive printer identification scheme for halftone images. In IEEE International Conference on Image Processing (ICIP), 2017
Timo Richter* , Stephan Escher* , Dagmar Schönfeld, Thorsten Strufe. Forensic Analysis and Anonymisation of Printed Documents. In Proceedings of 6th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ’18), 2018
Stephan Escher, Patrick Teufert, Lukas Hain, Thorsten Strufe. Twizzle - A Multi-Purpose Benchmarking Framework for Semantic Comparisons of Multimedia Object Pairs. In Proceedings of 3rd International Workshop on Multimedia Privacy and Security (MPS), 2020
Stephan Escher, Patrick Teufert, Robin Hermann, Thorsten Strufe. You've got nothing on me! Privacy Friendly Face Recognition Reloaded. In Proceedings of 3rd International Workshop on Multimedia Privacy and Security (MPS), 2020
Description: The deda toolkit enables automatic extraction, decoding and anonymisation of document colour tracking dots
If you use this software, please cite the paper:
Timo Richter*, Stephan Escher*, Dagmar
Schönfeld and Thorsten Strufe. 2018. Forensic Analysis and Anonymisation of Printed Documents.
In Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec
'18). ACM, New York, NY, USA, 127-138. DOI
Github-Link Download Windows Exe
Example for Ubuntu 16.10 or newer
Example for Windows 10
Description: The modular Image Hashing Benchmarking System MIHBS makes it possible to compare and evaluate perceptual hashing approaches regarding their robustness against specific perceptual preserving transformations, their sensitivity and specific labeled application datasets.
3f32f892d1c64a97890af89746041b69
Description: A modular Challenge-Response Benchmarking System for pairwise object comparisons. Usable to compare and evaluate for example Perceptual Hashing, Printer Forensics or Face Recognition algorithms.
Description: Different Datasets for development and evaluation of printer forensic algorithms.
Nöthnitzer Str. 46
Andreas-Pfitzmann-Bau (APB)
Raum: 3072
01187 Dresden
+49 351 463 38111

